Iterative Decomposition Model V3
Table of Contents
Iterative Decomposition V3 Model
This article covers the continuation of work I've been pursuing in the area of sparse, interpretable audio models.
Some previous iterations of this work:
All training and model code can be
found here.
Our goal is to decompose a musical audio signal into a small number of "events", roughly analogous to a musical score,
but carrying information about the resonant characteristics of the instrument being played, and the room it is being
played in. Each event is represented by a low-dimensional (32, in this case) vector and a time at which the event
occurs in the "score".
We seek to achieve this goal by iteratively guessing at the next-most informative event, removing it from the original
signal, and repeating the process, until no informative/interesting signal is remaining.
This is very similar to the matching pursuit algorithm, where we
repeatedly convolve an audio signal with a dictionary of audio atoms, picking the most highly-correlated atom at each
step, removing it, and the repeating the process until the norm of the original signal reaches some acceptable
threshold.
The Algorithm
In this work, we replace the convolution of a large dictionary of audio "atoms" with analysis via a "deep" neural
network, which uses an STFT transform followed by
cascading dilated convolutions
to efficiently analyze relatively long audio segments. At each iteration, it proposes an event vector and a
time-of-occurrence. This event is then rendered by an event-generator network and scheduled, by convolving the
rendered event with a dirac function (unit-valued spike) at the desired time. It is subtracted from the original audio
spectrogram[^1], and the process is repeated. During training, this process runs for a fixed number of steps, but it's possible
to imagine a modification whereby some other stopping condition is observed to improve efficiency.
The decoder makes some simple physics-based assumptions about the underlying signal, and uses convolutions with long
kernels to model the transfer functions of the instruments and the rooms in which they are performed.
The Training Process
We train the model on ~three-second segments of audio from the
MusicNet dataset, which represents approximately 33 hours of
public-domain classical music. We optimize the model via gradient descent using the following training objectives:
- An iterative reconstruction loss, which asks the model to maximize the energy it removes from the signal at each step
- A sparsity loss, which asks the model to minimize the l1 norm of the event vectors, ideally leading to a sparse (few event) solution
- An adversarial loss, which masks about 50% of events and asks a discriminator network (trained in parallel) to
judge them; this is intended to encourage the events to be independent and stand on their own as believable, musical
events.
Improvements over the Previous Model
While the previous model only operated on around 1.5 seconds of audio, this model doubles that window, ultimately
driving toward a fully streaming algorithm that can handle signals of arbitrary length. It also makes progress toward
a much simpler decoder, which generates each event as a linear combination of lookup tables for the following elements:
- a noisy impulse, or injection of energy into the system
- some number of resonances, built by combining sine, sawtooth, triangle, and square waves
- an interpolation between the resonances, representing the deformation of the system/instrument being played (e.g, the bending of a violin string as vibrato)
- a pre-baked room impulse response, which is, in fact, just another transfer function, this time for the entire room or space in which the piece is played
Future Work
Model Size, Training Time and Dataset
Firstly, this model is relatively small, weighing in at ~26M parameters (~117 MB on disk) and has only been trained for
around 24 hours, so it seems there is a lot of space to increase the model size, dataset size and training time to
further improve. The reconstruction quality of the examples on this page is not amazing, certainly not good enough
even for a lossy audio codec, but the structure the model extracts seems like it could be used for many interesting
applications.
Streaming and/or Arbitrary Lengths
Ultimately, the model should be able to handle audio segments of arbitrary lengths, adhering to some event "budget" to
find the sparsest-possible explanation of the audio segment.
A Better Sparsity Loss
Some of the examples lead me to believe that my current sparsity loss is too aggressive; the model sometimes prefers
to leave events out entirely rather than get the "win" of reducing overall signal energy. Using the l1 norm penalty
seems like a sledgehammer, and a more nuanced loss would probably do better.
Different Event Generator Variants
The decoder side of the model is very interesting, and all sorts of physical modelling-like approaches could yield
better, more realistic, and sparser renderings of the audio.
Cite this Article
If you'd like to cite this article, you can use the following BibTeX block.
Event Scatterplot
Here is a scatterplot mapping events from four different audio segments onto a 2D plane using t-SNE.
Each 32-dimensional event vector encodes information about attack, resonance, and room impulse response.
Examples
Example 1
Original Audio
Reconstruction
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
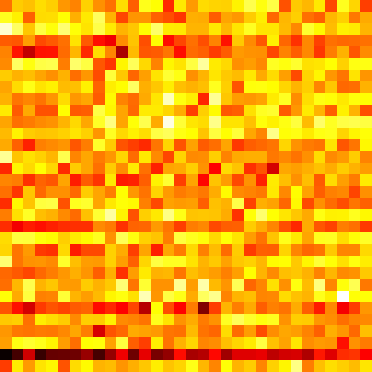
Event Vectors
Event Scatterplot
Events clustered using t-SNE
Individual Audio Events
Example 2
Original Audio
Reconstruction
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
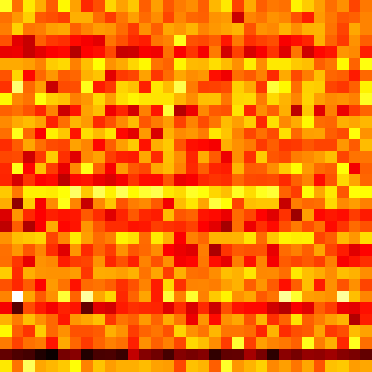
Event Vectors
Event Scatterplot
Events clustered using t-SNE
Individual Audio Events
Example 3
Original Audio
Reconstruction
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
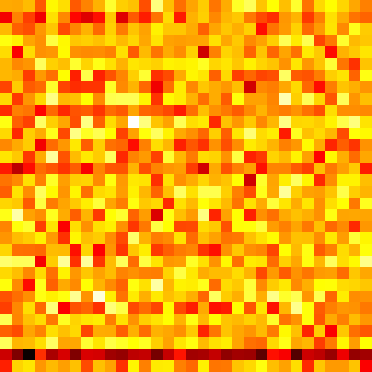
Event Vectors
Event Scatterplot
Events clustered using t-SNE
Individual Audio Events
Example 4
Original Audio
Reconstruction
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
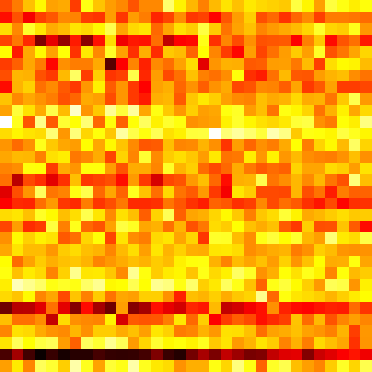
Event Vectors
Event Scatterplot
Events clustered using t-SNE
Individual Audio Events
Example 5
Original Audio
Reconstruction
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors

Event Scatterplot
Events clustered using t-SNE
Individual Audio Events
# the size, in samples of the audio segment we'll overfit
n_samples = 2 ** 16
samples_per_event = 2048
n_events = n_samples // samples_per_event
context_dim = 32
# the samplerate, in hz, of the audio signal
samplerate = 22050
# derived, the total number of seconds of audio
n_seconds = n_samples / samplerate
transform_window_size = 2048
transform_step_size = 256
n_frames = n_samples // transform_step_size
from argparse import ArgumentParser
from typing import Dict, Tuple
import numpy as np
import torch
from sklearn.manifold import TSNE
from torch import nn
from conjure import S3Collection, \
conjure_article, CitationComponent, AudioComponent, ImageComponent, \
CompositeComponent, Logger, ScatterPlotComponent
from data import get_one_audio_segment, AudioIterator
from iterativedecomposition import Model as IterativeDecompositionModel
from modules.eventgenerators.overfitresonance import OverfitResonanceModel
from modules import max_norm, sparse_softmax
remote_collection_name = 'iterative-decomposition-v3'
def to_numpy(x: torch.Tensor):
return x.data.cpu().numpy()
# thanks to https://discuss.pytorch.org/t/how-do-i-check-the-number-of-parameters-of-a-model/4325/9
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def process_events(
vectors: torch.Tensor,
times: torch.Tensor,
total_seconds: float) -> Tuple:
positions = torch.argmax(times, dim=-1, keepdim=True) / times.shape[-1]
times = [float(x) for x in (positions * total_seconds).view(-1).data.cpu().numpy()]
normalized = vectors.data.cpu().numpy().reshape((-1, context_dim))
normalized = normalized - normalized.min(axis=0, keepdims=True)
normalized = normalized / (normalized.max(axis=0, keepdims=True) + 1e-8)
tsne = TSNE(n_components=2)
points = tsne.fit_transform(normalized)
proj = np.random.uniform(0, 1, (2, 3))
colors = points @ proj
colors -= colors.min()
colors /= (colors.max() + 1e-8)
colors *= 255
colors = colors.astype(np.uint8)
colors = [f'rgb({c[0]} {c[1]} {c[2]})' for c in colors]
return points, times, colors
def load_model(wavetable_device: str = 'cpu') -> nn.Module:
hidden_channels = 512
model = IterativeDecompositionModel(
in_channels=1024,
hidden_channels=hidden_channels,
resonance_model=OverfitResonanceModel(
n_noise_filters=32,
noise_expressivity=8,
noise_filter_samples=128,
noise_deformations=16,
instr_expressivity=8,
n_events=1,
n_resonances=4096,
n_envelopes=256,
n_decays=32,
n_deformations=32,
n_samples=n_samples,
n_frames=n_frames,
samplerate=samplerate,
hidden_channels=hidden_channels,
wavetable_device=wavetable_device,
fine_positioning=True
))
with open('iterativedecomposition4.dat', 'rb') as f:
model.load_state_dict(torch.load(f, map_location=lambda storage, loc: storage))
print('Total parameters', count_parameters(model))
print('Encoder parameters', count_parameters(model.encoder))
print('Decoder parameters', count_parameters(model.resonance))
return model
def scatterplot_section(logger: Logger) -> ScatterPlotComponent:
model = load_model()
ai = AudioIterator(
batch_size=4,
n_samples=n_samples,
samplerate=22050,
normalize=True,
as_torch=True)
batch = next(iter(ai))
batch = batch.view(-1, 1, n_samples).to('cpu')
events, vectors, times = model.iterative(batch)
total_seconds = n_samples / samplerate
points, times, colors = process_events(vectors, times, total_seconds)
events = events.view(-1, n_samples)
events = {f'event{i}': events[i: i + 1, :] for i in range(events.shape[0])}
scatterplot_srcs = []
event_components = {}
for k, v in events.items():
_, e = logger.log_sound(k, v)
scatterplot_srcs.append(e.public_uri)
event_components[k] = AudioComponent(e.public_uri, height=35, controls=False)
scatterplot_component = ScatterPlotComponent(
scatterplot_srcs,
width=500,
height=500,
radius=0.3,
points=points,
times=times,
colors=colors, )
return scatterplot_component
def generate_multiple_events(
model: nn.Module,
vectors: torch.Tensor,
times: torch.Tensor) -> torch.Tensor:
generation_result = torch.cat(
[model.generate(vectors[:, i:i + 1, :], times[:, i:i + 1, :]) for i in range(n_events)], dim=1)
generation_result = torch.sum(generation_result, dim=1, keepdim=True)
generation_result = max_norm(generation_result)
return generation_result
def generate(
model: nn.Module,
vectors: torch.Tensor,
times: torch.Tensor,
randomize_events: bool,
randomize_times: bool) -> torch.Tensor:
batch, n_events, _ = vectors.shape
if randomize_events:
vectors = torch.zeros_like(vectors).uniform_(vectors.min().item(), vectors.max().item())
if randomize_times:
times = torch.zeros_like(times).uniform_(-1, 1)
times = sparse_softmax(times, dim=-1, normalize=True) * times
# generation_result = torch.cat(
# [model.generate(vectors[:, i:i + 1, :], times[:, i:i + 1, :]) for i in range(n_events)], dim=1)
# generation_result = torch.sum(generation_result, dim=1, keepdim=True)
# generation_result = max_norm(generation_result)
generation_result = generate_multiple_events(model, vectors, times)
return generation_result
def reconstruction_section(logger: Logger) -> CompositeComponent:
model = load_model()
# get a random audio segment
samples = get_one_audio_segment(n_samples, samplerate, device='cpu').view(1, 1, n_samples)
events, vectors, times = model.iterative(samples)
# generate audio with the same times, but randomized event vectors
randomized_events = generate(model, vectors, times, randomize_events=True, randomize_times=False)
_, random_events = logger.log_sound('randomizedevents', randomized_events)
random_events_component = AudioComponent(random_events.public_uri, height=100, controls=True)
# generate audio with the same events, but randomized times
randomized_times = generate(model, vectors, times, randomize_events=False, randomize_times=True)
_, random_times = logger.log_sound('randomizedtimes', randomized_times)
random_times_component = AudioComponent(random_times.public_uri, height=100, controls=True)
total_seconds = n_samples / samplerate
points, times, colors = process_events(vectors, times, total_seconds)
# sum together all events
summed = torch.sum(events, dim=1, keepdim=True)
_, original = logger.log_sound(f'original', samples)
_, reconstruction = logger.log_sound(f'reconstruction', summed)
orig_audio_component = AudioComponent(original.public_uri, height=100)
recon_audio_component = AudioComponent(reconstruction.public_uri, height=100)
events = {f'event{i}': events[:, i: i + 1, :] for i in range(events.shape[1])}
scatterplot_srcs = []
event_components = {}
for k, v in events.items():
_, e = logger.log_sound(k, v)
scatterplot_srcs.append(e.public_uri)
event_components[k] = AudioComponent(e.public_uri, height=25, controls=False)
scatterplot_component = ScatterPlotComponent(
scatterplot_srcs,
width=300,
height=300,
radius=0.04,
points=points,
times=times,
colors=colors, )
_, event_vectors = logger.log_matrix_with_cmap('latents', vectors[0].T, cmap='hot')
latents = ImageComponent(event_vectors.public_uri, height=200, title='latent event vectors')
composite = CompositeComponent(
orig_audio=orig_audio_component,
recon_audio=recon_audio_component,
latents=latents,
scatterplot=scatterplot_component,
random_events=random_events_component,
random_times=random_times_component,
**event_components
)
return composite
Notes
This blog post is generated from a
Python script using
conjure.
[^1]: While the STFT (short-time fourier transform) doesn't capture everything of perceptual import, it does a fairly
good job, better than the "raw", time-domain audio signal, at least. In the time domain, we get into trouble when we
begin to try to represent and remove the noisier parts of the signal; here the statistics and relationships between
different auditory bandpass filters become more important than the precise amplitude values.
def demo_page_dict() -> Dict[str, any]:
print(f'Generating article...')
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
logger = Logger(remote)
print('Creating large scatterplot')
large_scatterplot = scatterplot_section(logger)
print('Creating reconstruction examples')
example_1 = reconstruction_section(logger)
example_2 = reconstruction_section(logger)
example_3 = reconstruction_section(logger)
example_4 = reconstruction_section(logger)
example_5 = reconstruction_section(logger)
citation = CitationComponent(
tag='johnvinyarditerativedecompositionv3',
author='Vinyard, John',
url='https://blog.cochlea.xyz/iterative-decomposition-v3.html',
header='Iterative Decomposition V3',
year='2024',
)
return dict(
large_scatterplot=large_scatterplot,
example_1=example_1,
example_2=example_2,
example_3=example_3,
example_4=example_4,
example_5=example_5,
citation=citation
)
def generate_demo_page():
display = demo_page_dict()
conjure_article(
__file__,
'html',
title='Iterative Decomposition Model V3',
**display)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--clear', action='store_true')
parser.add_argument('--list', action='store_true')
args = parser.parse_args()
if args.list:
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
print(remote)
print('Listing stored keys')
for key in remote.iter_prefix(start_key=b'', prefix=b''):
print(key)
if args.clear:
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
remote.destroy(prefix=b'')
generate_demo_page()
Back to Top