Toward a Sparse Interpretable Audio Codec (Speech Examples)
Table of Contents
Speech Samples
Early samples (~24 hours of training) from the LJ Speech Dataset.
These samples elucidate a couple primary issues to be addressed:
- The sparsity penalty is not high enough, resulting in redundant/overlapping events and attendant phase issues
- Because the resonance model in the decoder is essentially wavetable synthesis, we'll need a way for the decoder to more directly control the "phase" of the read-head
Primary content about the model and classical musical examples can be found here
Cite this Article
If you'd like to cite this article, you can use the following BibTeX block.
Audio Examples
Example 1
Original Audio
Reconstruction
We mask the second half of the input audio to enable the streaming algorithm, so only the first half of the input audio is reproduced.
Decomposition
We can see that while energy is removed at each step, removed segments do not map cleanly onto audio "events" as a human listener would typically conceive of them. Future work will move toward fewer and more meaningul events via induced sparsity and/or clustering of events.

Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors
Different stopping conditions might be chosen during inference (e.g. norm of the residual) but during training, we remove energy for 32 steps. Each event vector is of dimension 32. The decoder generates an event from this vector, which is then scheduled.

Event Scatterplot
Time is along the x-axis, and a 32D -> 1D projection of event vectors using t-SNE constitutes the distribution along the y-axis. Colors are produced via a random projection from 32D -> 3D (RGB). Here it becomes clear that there are many redundant/overlapping events. Future work will stress more sparsity and less event overlap, hopefully increasing interpretability further.
Example 2
Original Audio
Reconstruction
We mask the second half of the input audio to enable the streaming algorithm, so only the first half of the input audio is reproduced.
Decomposition
We can see that while energy is removed at each step, removed segments do not map cleanly onto audio "events" as a human listener would typically conceive of them. Future work will move toward fewer and more meaningul events via induced sparsity and/or clustering of events.

Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors
Different stopping conditions might be chosen during inference (e.g. norm of the residual) but during training, we remove energy for 32 steps. Each event vector is of dimension 32. The decoder generates an event from this vector, which is then scheduled.

Event Scatterplot
Time is along the x-axis, and a 32D -> 1D projection of event vectors using t-SNE constitutes the distribution along the y-axis. Colors are produced via a random projection from 32D -> 3D (RGB). Here it becomes clear that there are many redundant/overlapping events. Future work will stress more sparsity and less event overlap, hopefully increasing interpretability further.
Example 3
Original Audio
Reconstruction
We mask the second half of the input audio to enable the streaming algorithm, so only the first half of the input audio is reproduced.
Decomposition
We can see that while energy is removed at each step, removed segments do not map cleanly onto audio "events" as a human listener would typically conceive of them. Future work will move toward fewer and more meaningul events via induced sparsity and/or clustering of events.

Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors
Different stopping conditions might be chosen during inference (e.g. norm of the residual) but during training, we remove energy for 32 steps. Each event vector is of dimension 32. The decoder generates an event from this vector, which is then scheduled.
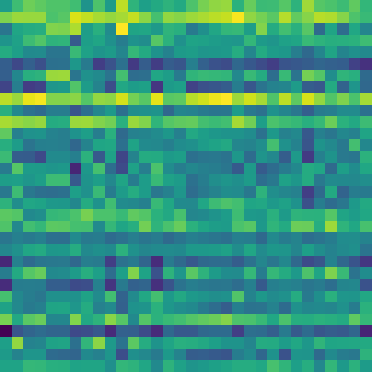
Event Scatterplot
Time is along the x-axis, and a 32D -> 1D projection of event vectors using t-SNE constitutes the distribution along the y-axis. Colors are produced via a random projection from 32D -> 3D (RGB). Here it becomes clear that there are many redundant/overlapping events. Future work will stress more sparsity and less event overlap, hopefully increasing interpretability further.
Example 4
Original Audio
Reconstruction
We mask the second half of the input audio to enable the streaming algorithm, so only the first half of the input audio is reproduced.
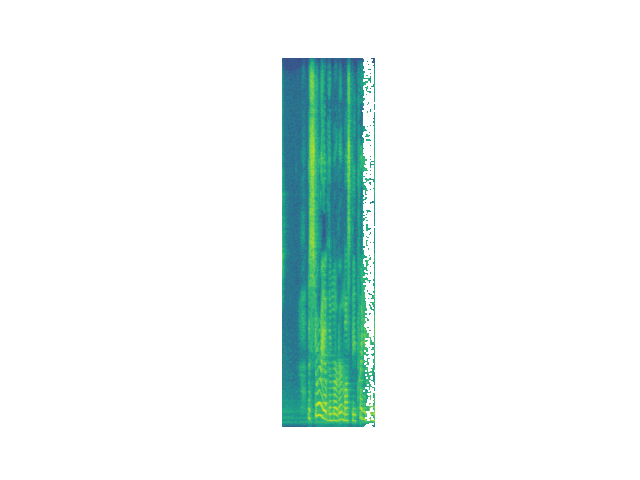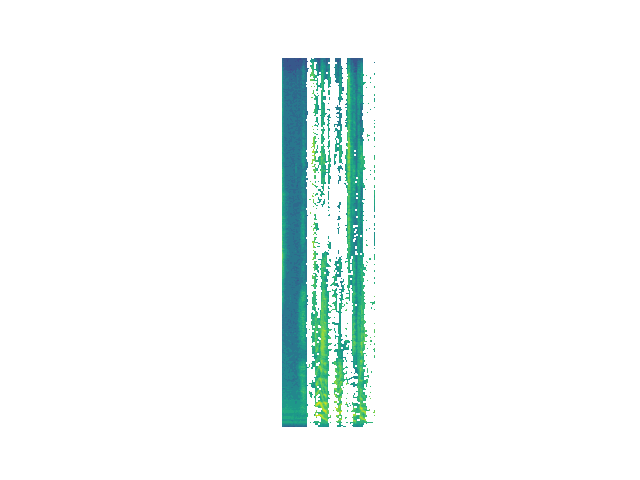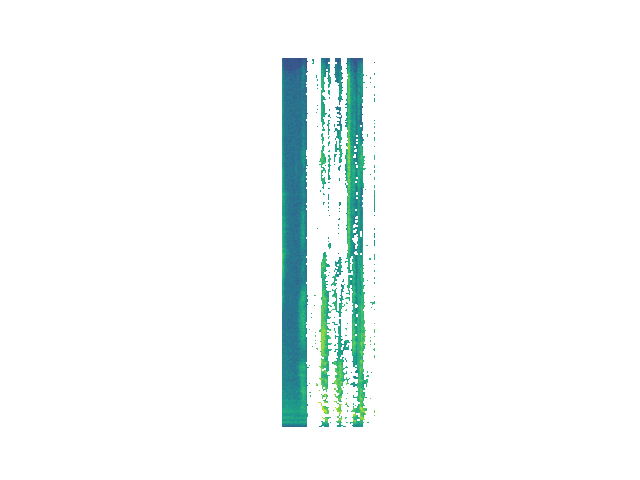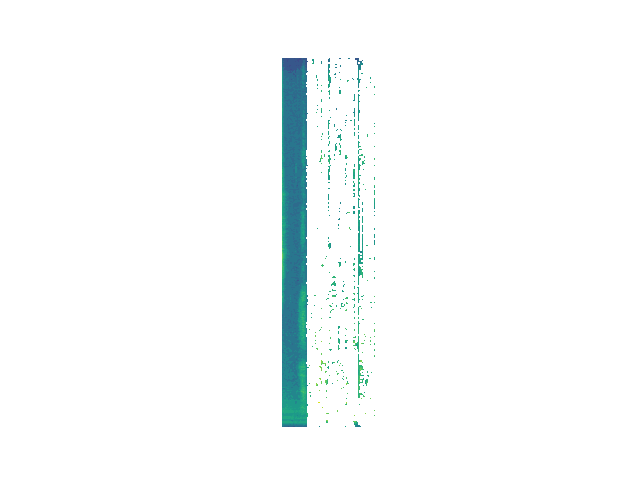
Decomposition
We can see that while energy is removed at each step, removed segments do not map cleanly onto audio "events" as a human listener would typically conceive of them. Future work will move toward fewer and more meaningul events via induced sparsity and/or clustering of events.

Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors
Different stopping conditions might be chosen during inference (e.g. norm of the residual) but during training, we remove energy for 32 steps. Each event vector is of dimension 32. The decoder generates an event from this vector, which is then scheduled.

Event Scatterplot
Time is along the x-axis, and a 32D -> 1D projection of event vectors using t-SNE constitutes the distribution along the y-axis. Colors are produced via a random projection from 32D -> 3D (RGB). Here it becomes clear that there are many redundant/overlapping events. Future work will stress more sparsity and less event overlap, hopefully increasing interpretability further.
Example 5
Original Audio
Reconstruction
We mask the second half of the input audio to enable the streaming algorithm, so only the first half of the input audio is reproduced.
Decomposition
We can see that while energy is removed at each step, removed segments do not map cleanly onto audio "events" as a human listener would typically conceive of them. Future work will move toward fewer and more meaningul events via induced sparsity and/or clustering of events.
Randomized
Here, we generate random event vectors with the original event times.
Here we use the original event vectors, but generate random times.
Event Vectors
Different stopping conditions might be chosen during inference (e.g. norm of the residual) but during training, we remove energy for 32 steps. Each event vector is of dimension 32. The decoder generates an event from this vector, which is then scheduled.

Event Scatterplot
Time is along the x-axis, and a 32D -> 1D projection of event vectors using t-SNE constitutes the distribution along the y-axis. Colors are produced via a random projection from 32D -> 3D (RGB). Here it becomes clear that there are many redundant/overlapping events. Future work will stress more sparsity and less event overlap, hopefully increasing interpretability further.
n_samples = 2 ** 17
samples_per_event = 2048
# this is cut in half since we'll mask out the second half of encoder activations
n_events = (n_samples // samples_per_event) // 2
context_dim = 32
# the samplerate, in hz, of the audio signal
samplerate = 22050
# derived, the total number of seconds of audio
n_seconds = n_samples / samplerate
transform_window_size = 2048
transform_step_size = 256
n_frames = n_samples // transform_step_size
from argparse import ArgumentParser
from typing import Dict, Tuple
import numpy as np
import torch
from sklearn.manifold import TSNE
from torch import nn
from conjure import S3Collection, \
conjure_article, CitationComponent, AudioComponent, ImageComponent, \
CompositeComponent, Logger, ScatterPlotComponent
from data import get_one_audio_segment, AudioIterator
from iterativedecomposition import Model as IterativeDecompositionModel
from modules.eventgenerators.overfitresonance import OverfitResonanceModel
from modules import max_norm, sparse_softmax
remote_collection_name = 'iterative-decomposition-v3'
def to_numpy(x: torch.Tensor):
return x.data.cpu().numpy()
# thanks to https://discuss.pytorch.org/t/how-do-i-check-the-number-of-parameters-of-a-model/4325/9
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
def process_events(
vectors: torch.Tensor,
times: torch.Tensor,
total_seconds: float) -> Tuple:
positions = torch.argmax(times, dim=-1, keepdim=True) / times.shape[-1]
times = [float(x) for x in (positions * total_seconds).view(-1).data.cpu().numpy()]
normalized = vectors.data.cpu().numpy().reshape((-1, context_dim))
normalized = normalized - normalized.min(axis=0, keepdims=True)
normalized = normalized / (normalized.max(axis=0, keepdims=True) + 1e-8)
tsne = TSNE(n_components=1)
points = tsne.fit_transform(normalized)
proj = np.random.uniform(0, 1, (context_dim, 3))
colors = normalized @ proj
colors -= colors.min()
colors /= (colors.max() + 1e-8)
colors *= 255
colors = colors.astype(np.uint8)
colors = [f'rgba({c[0]}, {c[1]}, {c[2]}, 0.5)' for c in colors]
t = np.array(times) / total_seconds
points = np.concatenate([points.reshape((-1, 1)), t.reshape((-1, 1))], axis=-1)
return points, times, colors
def load_model(wavetable_device: str = 'cpu') -> nn.Module:
hidden_channels = 512
model = IterativeDecompositionModel(
in_channels=1024,
hidden_channels=hidden_channels,
resonance_model=OverfitResonanceModel(
n_noise_filters=64,
noise_expressivity=4,
noise_filter_samples=128,
noise_deformations=32,
instr_expressivity=4,
n_events=1,
n_resonances=4096,
n_envelopes=64,
n_decays=64,
n_deformations=64,
n_samples=n_samples,
n_frames=n_frames,
samplerate=samplerate,
hidden_channels=hidden_channels,
wavetable_device=wavetable_device,
fine_positioning=True,
fft_resonance=True
))
with open('iterativedecomposition_speech.dat', 'rb') as f:
model.load_state_dict(torch.load(f, map_location=lambda storage, loc: storage))
print('Total parameters', count_parameters(model))
print('Encoder parameters', count_parameters(model.encoder))
print('Decoder parameters', count_parameters(model.resonance))
return model
def scatterplot_section(logger: Logger) -> ScatterPlotComponent:
model = load_model()
ai = AudioIterator(
batch_size=4,
n_samples=n_samples,
samplerate=22050,
normalize=True,
as_torch=True)
batch = next(iter(ai))
batch = batch.view(-1, 1, n_samples).to('cpu')
events, vectors, times = model.iterative(batch)
total_seconds = n_samples / samplerate
points, times, colors = process_events(vectors, times, total_seconds)
events = events.view(-1, n_samples)
events = {f'event{i}': events[i: i + 1, :] for i in range(events.shape[0])}
scatterplot_srcs = []
event_components = {}
for k, v in events.items():
_, e = logger.log_sound(k, v)
scatterplot_srcs.append(e.public_uri)
event_components[k] = AudioComponent(e.public_uri, height=35, controls=False)
scatterplot_component = ScatterPlotComponent(
scatterplot_srcs,
width=800,
height=400,
radius=0.01,
points=points,
times=times,
colors=colors,
with_duration=True)
print(scatterplot_component, 'WITH_DURATION', scatterplot_component.with_duration)
return scatterplot_component
def generate_multiple_events(
model: nn.Module,
vectors: torch.Tensor,
times: torch.Tensor) -> torch.Tensor:
generation_result = torch.cat(
[model.generate(vectors[:, i:i + 1, :], times[:, i:i + 1, :]) for i in range(n_events)], dim=1)
generation_result = torch.sum(generation_result, dim=1, keepdim=True)
generation_result = max_norm(generation_result)
return generation_result
def generate(
model: nn.Module,
vectors: torch.Tensor,
times: torch.Tensor,
randomize_events: bool,
randomize_times: bool) -> torch.Tensor:
batch, n_events, _ = vectors.shape
if randomize_events:
vectors = torch.zeros_like(vectors).uniform_(vectors.min().item(), vectors.max().item())
if randomize_times:
times = torch.zeros_like(times).uniform_(-1, 1)
times = sparse_softmax(times, dim=-1, normalize=True) * times
generation_result = generate_multiple_events(model, vectors, times)
return generation_result
def streaming_section(logger: Logger) -> CompositeComponent:
model = load_model()
samples = get_one_audio_segment(n_samples * 4, samplerate, device='cpu').view(1, 1, -1)
with torch.no_grad():
recon = model.streaming(samples)
recon = max_norm(recon)
_, orig = logger.log_sound(key='streamingorig', audio=samples)
orig = AudioComponent(orig.public_uri, height=100, controls=True, scale=4)
_, recon = logger.log_sound(key='streamingrecon', audio=recon)
recon = AudioComponent(recon.public_uri, height=100, controls=True, scale=4)
return CompositeComponent(
orig=orig,
recon=recon,
)
def reconstruction_section(logger: Logger) -> CompositeComponent:
model = load_model()
# get a random audio segment
samples = get_one_audio_segment(n_samples, samplerate, device='cpu').view(1, 1, n_samples)
events, vectors, times, residuals = model.iterative(samples, return_all_residuals=True)
residuals = residuals.view(n_events, 1024, -1).data.cpu().numpy()
residuals = residuals[:, ::-1, :]
print('RESIDUAL', residuals.min(), residuals.max())
residuals = np.log(residuals + 1e-6)
t = residuals.shape[-1]
residuals = residuals[..., :t // 2]
_, movie = logger.log_movie('decomposition', residuals, fps=2)
movie = ImageComponent(movie.public_uri, height=200, title='decomposition')
# generate audio with the same times, but randomized event vectors
randomized_events = generate(model, vectors, times, randomize_events=True, randomize_times=False)
_, random_events = logger.log_sound('randomizedevents', randomized_events)
random_events_component = AudioComponent(random_events.public_uri, height=100, controls=True)
# generate audio with the same events, but randomized times
randomized_times = generate(model, vectors, times, randomize_events=False, randomize_times=True)
_, random_times = logger.log_sound('randomizedtimes', randomized_times)
random_times_component = AudioComponent(random_times.public_uri, height=100, controls=True)
total_seconds = n_samples / samplerate
points, times, colors = process_events(vectors, times, total_seconds)
# sum together all events
summed = torch.sum(events, dim=1, keepdim=True)
summed = max_norm(summed)
_, original = logger.log_sound(f'original', samples)
_, reconstruction = logger.log_sound(f'reconstruction', summed)
orig_audio_component = AudioComponent(original.public_uri, height=100)
recon_audio_component = AudioComponent(reconstruction.public_uri, height=100)
events = {f'event{i}': events[:, i: i + 1, :] for i in range(events.shape[1])}
scatterplot_srcs = []
event_components = {}
for k, v in events.items():
_, e = logger.log_sound(k, v)
scatterplot_srcs.append(e.public_uri)
event_components[k] = AudioComponent(e.public_uri, height=15, controls=False)
scatterplot_component = ScatterPlotComponent(
scatterplot_srcs,
width=600,
height=300,
radius=0.03,
points=points,
times=times,
colors=colors,
with_duration=False)
print('WITH DURATION', scatterplot_component.with_duration)
_, event_vectors = logger.log_matrix_with_cmap('latents', vectors[0].T, cmap='viridis')
latents = ImageComponent(event_vectors.public_uri, height=200, title='latent event vectors', full_width=False)
composite = CompositeComponent(
orig_audio=orig_audio_component,
recon_audio=recon_audio_component,
latents=latents,
scatterplot=scatterplot_component,
random_events=random_events_component,
random_times=random_times_component,
decomposition=movie,
**event_components
)
return composite
Notes
This blog post is generated from a
Python script using
conjure.
def demo_page_dict() -> Dict[str, any]:
print(f'Generating article...')
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
logger = Logger(remote)
# print('Creating large scatterplot')
# large_scatterplot = scatterplot_section(logger)
print('Creating streaming section')
streaming = streaming_section(logger)
print('Creating reconstruction examples')
example_1 = reconstruction_section(logger)
example_2 = reconstruction_section(logger)
example_3 = reconstruction_section(logger)
example_4 = reconstruction_section(logger)
example_5 = reconstruction_section(logger)
citation = CitationComponent(
tag='johnvinyarditerativedecompositionv3',
author='Vinyard, John',
url='https://blog.cochlea.xyz/sparse-interpretable-audio-codec-paper.html',
header='Toward a Sparse Interpretable Audio Codec (Speech Examples)',
year='2025',
)
return dict(
streaming=streaming,
example_1=example_1,
example_2=example_2,
example_3=example_3,
example_4=example_4,
example_5=example_5,
citation=citation
)
def generate_demo_page():
display = demo_page_dict()
conjure_article(
__file__,
'html',
title='Toward a Sparse Interpretable Audio Codec (Speech Examples)',
**display)
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--clear', action='store_true')
parser.add_argument('--list', action='store_true')
args = parser.parse_args()
if args.list:
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
print(remote)
print('Listing stored keys')
for key in remote.iter_prefix(start_key=b'', prefix=b''):
print(key)
if args.clear:
remote = S3Collection(
remote_collection_name, is_public=True, cors_enabled=True)
remote.destroy(prefix=b'')
generate_demo_page()
Back to Top